
奖励模型终于进入了一个新的培训期!上海AI实验
发布时间:2025-07-14 10:12
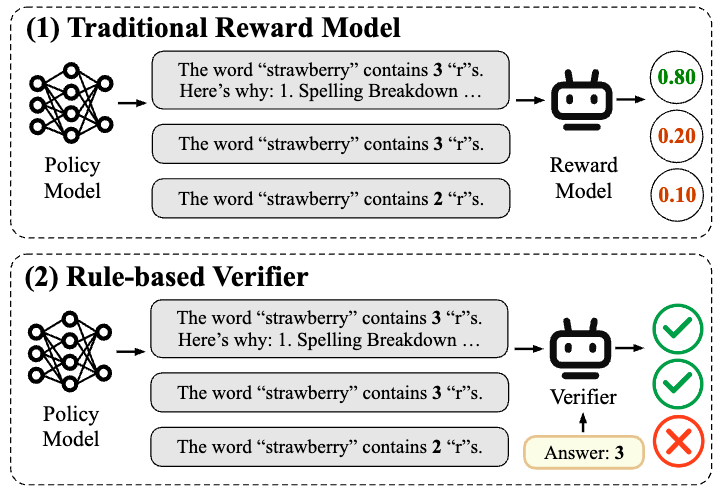 在大型语言模型的训练后阶段,强化研究已成为提高模型能力,使人类偏好保持一致并有望朝着AGI迈进的关键方法。但是,奖励模型的设计和培训始终是限制训练后影响的主要瓶颈。当前,奖励建模的基本方法包括两种方法:基于奖励和验证者的建模偏好。其中,“基于奖励的奖励偏好”通常使用带注释的偏好来培训奖励模型,并且该方法有许多局限性。首先,获得高质量偏好数据的成本非常高且难以衡量。其次,基于“主观完全偏好”的奖励建模在面对新任务,总体能力有限,并且非常容易受到“奖励黑客攻击”的影响。这些问题严重限制了在劳动后奖励模型的实际实施下雨阶段。借助诸如DeepSeek R1之类的引人注目的模型的成功,“基于规则的验证”加固方法(RLVR)始于广泛使用。 RLVR依靠给定问题的通常答案或预期行为来提供奖励,从而确保奖励信号的准确性。因此,RLVR特别适合具有清晰评估标准(例如数学推理和代码生成)的“经过验证”活动。但是,在现实世界中,很难验证规则,例如开放域对话,写作,复杂的联系等。这使得在更一般的情况下很难扩展基于证据的验证程序。基于奖励的基于奖励的建模很难衡量,并且通常很难满足一般方案的需求。那么,奖励建模解决方案到底是什么方便扩展的,并且非常普遍,并采用所有方案?图1:基于大型模型验证器(LLM)规则的传统奖励模型和评估的成功是,使用下一代币预测的形式团结所有任务并解决了无法普遍的各种任务表格的问题。奖励模型设计(RM)仍在重复传统解决方案的路径,尤其是标记特定RM情况的偏好数据和针对特定情况的培训。因此,我们可以按照LLM成功的途径重新设计RM训练范式吗?删除RM的“标记”标准就像删除LLM的“工作形式”,它发现一个更重要的优化目标函数与“预训练标记”标准分开,从而实现了真正的大学。 Kamakailan Lamang,Angkoponan ni Zou yicheng ng上海手工艺实验室实验室实验室,gui gui tao Team ng fudan University ay naglunsad ng na na na Modelo na Modelo na Modeo ng gantimpala na na na natagpuan angang isang iSANGANGANG ISANG iSANG ISANG BAGONG BAGONG MODERO NANG GANTIMPANNG GANTIMPANNG GANTIMPLO GANTIMPLO GANTIMPLAK Mula sa ganap na kagustuhan在Maaaring Maging tunay na Mahusay na pinalawak:Ang Patakaran ng diskriminatibong pag-aaral(Polar),Na Nagpapahintulot Sa Modeles由大语言模型奖励,它具有可扩展性和强大的一般能力。 Polar带来了后型模型培训中的发展成功,并有望打开最终的链接链接。纸质链接:https://arxiv.org/pdf/2507.05197项目链接:https://github.com/internlm/polar链接链接链接:https://huggingface.co/internlm/polar-polar-7bpolar是什么? - 研究结构歧视从完整的增强研究中衰减,接近方法确实是一个继续调整策略分布并逐渐接近最佳方法分布的过程。因此,当前候选人的方法和最佳方法之间的“距离”可以被视为潜在的奖励信号:候选人的方法越接近最好的notskarte,较高的奖励功能SHO给予ULD,从而指导策略以更好地团结最佳方向。通过衡量候选人的方法和最佳方法的目标之间的“距离”,我们可以建立一种奖励奖励的方法,该方法不取决于人类偏好的最大偏好,以便可以从“完全好的”中释放奖励模型,而是在接近目标策略的候选技术上提供更高的奖励标记。由于“距离”是一个相对性的概念,因此可能会意外地定义目标方法,从而摆脱依靠首选数据的管理 - 具有强大的潜在可扩展性。具体而言,极性使用轨迹是从候选技术到估计的pampercandidate技术的样本;同时,使用参考来估计方法的最佳分布。通过测量轨迹之间的差异来估计技术分布之间的距离。对于“距离度量”,t他的经典解决方案是“不同的研究”,它通过构建正面和负面例子来训练模型(例如剪辑)。 Polar是一种训练方案,该方案使用对比度研究对战略分布之间的“距离”进行建模。在这一点上,仍然存在最关键的问题之一:如何定义正面和负面的例子?如果是候选人方法的采样轨迹或代表最佳方法的参考参考,直接用于估计方法的分布将导致ILDIASES,因此我们无法衡量仅基于单个轨迹的两个相似性的示例。例如,在数学方案中,如果候选人方法的答复输出与参考文献相同,则可以说该方法是高质量的。但是,在高差异的情况下 - 与写作一样,如果候选人的方法每次都会发布相同的答案,则可以说该方法是低品质。因此,“如果轨迹相似”不能是公正的判断标准。在这方面,Polar采用了另一种解决方案:相同方法生成的轨迹被用作阳性示例,并且不同技术生成的轨迹被用作负面示例。尽管此判断标准有一定的反义,但它是一个相关的信号,如果在其上进行判断,则是正确的。样本相似。我们可以想象方法的模型是某个分布的公正采样器。尽管单个采样可以使噪声与正面和负面示例相反,但是当采样量表增加并扩展到大尺寸时,将更准确地描述分布之间的差异和距离。如图2所示,使用上面的研究方案将极性的预训练阶段扩展到大尺寸。同一模型的一对输出样本用作阳性示例,不同模型的样本输出用作负面示例,因此可以知道奖励模型以识别策略分布而不是完全偏好的模型。在此阶段不需要人类的偏好数据。仅引入SFT微调的第二阶段才能与人类的偏好保持一致。图2:如何训练极地研究歧视性政策? - 通过自动合成数据完全构建了移动和首选的预测极性体积。具体而言,从LLM预训练的语料库中采样了大量的文本前缀,并从池模型池(由开放资源131个基本LLM和53个CHAT LLMS)中随机捕获模型进行轨迹采样。预训练的目标使用Bradley-terry损失:其中A1和A2表示由相同方法模型产生的轨迹(正样品对); B1表示不同策略模型(负样本)产生的轨迹。这样,Polar允许RM为Mala人将更高的奖励分配给相似技术生成的轨迹,从而明确建模差异和距离分布方法。在此阶段,Polar-1.8b总共使用了0.94T令牌预训练数据,而Polar-7b总共使用了3.6吨令牌的预训练数据。在微调阶段,使用少量偏好数据将极性与人类偏好对齐。在同一提示中,三个轨迹是样品,偏好-in -law被标记。 Bradley-terry损失也用于微调:其中A B C分别代表首选,次优和最差的轨迹。这种类型的偏好明确指的是“策略差异”,因为可以将其视为最佳策略分布的一巴掌,而C将能够考虑远离最佳策略的策略发行的策略。图3:极性训练的两个阶段(预训练和偏好微调)以及如何在RFT中使用极性如何使用极性? - 完美适应增强曲调。加固微调(RFT)是极地的最佳使用情况。传统的奖励模型已完全保存,无法根据参考标记,并且很难应用于外部领域情况。 rlvr虽然可能是正确的,还是基于参考的答案和政策,但很难在一般任务中扩展。极性完全符合RFT增强学习框架,并根据参考答案对模型的输出进行建模。如果模型的输出更接近参考答案,请获得更多的奖励金额。通过此培训过程,候选方法可以逐渐转移到最佳方法。极性有多有效? - 偶尔性能保证和一般1。样本显示:闭门和开放问题。以下显示了闭合末端和开放问题下的极性-7b标记的效果,并且从高到低标记显示。考试ES的测试被完全认为是轨迹之间的各种陷阱和细微陷阱,在边界情况下测试了它们的标记精度。封闭的问题:问题:“草莓”一词有多少个“ r”?参考答案:“草莓”一词包含3个字母“ R”。我们可以按字母来计算字母:“ S”,“ T”,“ R”,“ A”,“ W”,“ B”,“ E”,“ R”,“ R”,“ R”,“ R”,“ Y”。因此,答案是3。轨迹1(与参考完全一致):“草莓”一词包含3个字母“ r”。我们可以按字母来计算字母:“ S”,“ T”,“ R”,“ A”,“ W”,“ B”,“ E”,“ R”,“ R”,“ R”,“ R”,“ Y”。因此,答案为3。得分:-1.5380859375轨迹2(正确,想法正确):我们将计算“草莓”:“ s”,“ t”,“ t”,“ r”,“ a”,“ w”,“ w”,“ b”,“ b”,“ b”,“ e”,“ e”,“ e”,r“ r”,“ r”,“ r”,“ r”,“ y”。这里有三个“ R”,所以有三个答案。质量:-2.767578125曲目3(正确答案,不想法):“草莓”一词中有3个“ r”标记:-7.45703125曲目4(答案是错误的,正确的想法):让我们计算一下单词“草莓” lot“ r”:“ s”,“ t”,“ r”,“”,“ w”,“”,“”“”,“ r”,“ y”。这里有三个“ r”。 “ B”,“ E”,“ R”,“ R”,“ R”,“ Y”。 “ y”。对应于参考):1。秋季2。下降3。下降3。下雨3(正确答案):1。下降2。下降3。倾盆大雨3(类似于reference, another): 1. Downpour 2. Downpour 3 (similar to Reference, another): 1. -Idio): 1. Fall 2. Flood payment 3. Falling Upis 4 (Non -Idio): 1. Torrential Rain Score: -6.609375 TrackThe six (similar to reference, repeat one): 1. Torrential Rain 2. Torrential Rain Score 3. Torrential Score :. -7.234375跟踪十个(一个雨词,一个含义不匹配):1。降雨得分:-7.234375监视十个(一个单词降雨,一个含义,一个含义不匹配):1。TorrentialRain 2。雨水和雨水3。百分比分别是,并且能够准确地确定一般活动中的轨迹上的细微差异,例如推理,聊天和创造性写作,并准确地预测人类的偏好。值得注意的是,只有1.8b参数,Polar-1.8b可以取得与Skywork-Reward-27b和World相当的结果PM-72B-ultrafeffexp(参数分别为15次和40次),具有强极潜力。 3。RFT应用:综合增强LLM图5:加强实验,并进行了精制调整,导致RFT实验,极性仍然比开放的SOTA奖励模型更好。例如,与所有基准上的WorldPM-72B-72B-72B-72B-72B-72B-72B-72B-72B-72B-72B-利曲FeppEADED优化相比,Polar-7b微调的Llama-3.1-8B平均相关的9.0%与初步结果相关的9.0%。极性可以确定策略模型与训练前阶段之间的细微差异,而不是仅依靠一对注释偏好,而是对实际RL应用中的概括信号奖励的显着增强。实验结果表明,尽管极性1.8b和Polar-7b在偏好分析中的性能相似,但Polar-7b也对RL的花朵实验显示出显着的好处。将影响从1.8b提高到7b进一步描述了效果极性具有的缩放尺度的CT。它还没有直接描述当前传统基准台的可能限制,也就是说,与真正的刺激研究方案有很大的差异。 4。比例尺的影响6:极性滚动法律在下一个目标预测中类似于LLM目标的极性iSdisplays尺度定律。这进一步反映了极地无监督的预训练方法的巨大潜力。在法律关系中,验证集的丢失随着增加参数模型n的力量而降低。适当的幂律函数为L =0.9ÅN^-0.0425,R2值为0.9886。验证集的丢失在与权力的法律关系中也降低了最佳的训练计算C.适当的幂律函数为L = 2.4·C^–0.0342,R2值为0.9912。这些结果表明,提供更多计算源将继续带来更好的RM性能。极地缩放率的巨大影响旨在发展其发展更一般和Malakas奖励模型的巨大潜力。结论极性可以通过比较训练阶段的学习技术之间的距离来对齐人类的偏好。在相使用期间,Polar使用RFT范式进行LLM增强研究,显示出极好的暴力。作为一种新的训练前训练的预训练方法,Polar为后LLM培训带来了新的可能性,从而提供了有效技能解决方案的整体RFT目标。预计将打开最终缩放链接RL链接。
在大型语言模型的训练后阶段,强化研究已成为提高模型能力,使人类偏好保持一致并有望朝着AGI迈进的关键方法。但是,奖励模型的设计和培训始终是限制训练后影响的主要瓶颈。当前,奖励建模的基本方法包括两种方法:基于奖励和验证者的建模偏好。其中,“基于奖励的奖励偏好”通常使用带注释的偏好来培训奖励模型,并且该方法有许多局限性。首先,获得高质量偏好数据的成本非常高且难以衡量。其次,基于“主观完全偏好”的奖励建模在面对新任务,总体能力有限,并且非常容易受到“奖励黑客攻击”的影响。这些问题严重限制了在劳动后奖励模型的实际实施下雨阶段。借助诸如DeepSeek R1之类的引人注目的模型的成功,“基于规则的验证”加固方法(RLVR)始于广泛使用。 RLVR依靠给定问题的通常答案或预期行为来提供奖励,从而确保奖励信号的准确性。因此,RLVR特别适合具有清晰评估标准(例如数学推理和代码生成)的“经过验证”活动。但是,在现实世界中,很难验证规则,例如开放域对话,写作,复杂的联系等。这使得在更一般的情况下很难扩展基于证据的验证程序。基于奖励的基于奖励的建模很难衡量,并且通常很难满足一般方案的需求。那么,奖励建模解决方案到底是什么方便扩展的,并且非常普遍,并采用所有方案?图1:基于大型模型验证器(LLM)规则的传统奖励模型和评估的成功是,使用下一代币预测的形式团结所有任务并解决了无法普遍的各种任务表格的问题。奖励模型设计(RM)仍在重复传统解决方案的路径,尤其是标记特定RM情况的偏好数据和针对特定情况的培训。因此,我们可以按照LLM成功的途径重新设计RM训练范式吗?删除RM的“标记”标准就像删除LLM的“工作形式”,它发现一个更重要的优化目标函数与“预训练标记”标准分开,从而实现了真正的大学。 Kamakailan Lamang,Angkoponan ni Zou yicheng ng上海手工艺实验室实验室实验室,gui gui tao Team ng fudan University ay naglunsad ng na na na Modelo na Modelo na Modeo ng gantimpala na na na natagpuan angang isang iSANGANGANG ISANG iSANG ISANG BAGONG BAGONG MODERO NANG GANTIMPANNG GANTIMPANNG GANTIMPLO GANTIMPLO GANTIMPLAK Mula sa ganap na kagustuhan在Maaaring Maging tunay na Mahusay na pinalawak:Ang Patakaran ng diskriminatibong pag-aaral(Polar),Na Nagpapahintulot Sa Modeles由大语言模型奖励,它具有可扩展性和强大的一般能力。 Polar带来了后型模型培训中的发展成功,并有望打开最终的链接链接。纸质链接:https://arxiv.org/pdf/2507.05197项目链接:https://github.com/internlm/polar链接链接链接:https://huggingface.co/internlm/polar-polar-7bpolar是什么? - 研究结构歧视从完整的增强研究中衰减,接近方法确实是一个继续调整策略分布并逐渐接近最佳方法分布的过程。因此,当前候选人的方法和最佳方法之间的“距离”可以被视为潜在的奖励信号:候选人的方法越接近最好的notskarte,较高的奖励功能SHO给予ULD,从而指导策略以更好地团结最佳方向。通过衡量候选人的方法和最佳方法的目标之间的“距离”,我们可以建立一种奖励奖励的方法,该方法不取决于人类偏好的最大偏好,以便可以从“完全好的”中释放奖励模型,而是在接近目标策略的候选技术上提供更高的奖励标记。由于“距离”是一个相对性的概念,因此可能会意外地定义目标方法,从而摆脱依靠首选数据的管理 - 具有强大的潜在可扩展性。具体而言,极性使用轨迹是从候选技术到估计的pampercandidate技术的样本;同时,使用参考来估计方法的最佳分布。通过测量轨迹之间的差异来估计技术分布之间的距离。对于“距离度量”,t他的经典解决方案是“不同的研究”,它通过构建正面和负面例子来训练模型(例如剪辑)。 Polar是一种训练方案,该方案使用对比度研究对战略分布之间的“距离”进行建模。在这一点上,仍然存在最关键的问题之一:如何定义正面和负面的例子?如果是候选人方法的采样轨迹或代表最佳方法的参考参考,直接用于估计方法的分布将导致ILDIASES,因此我们无法衡量仅基于单个轨迹的两个相似性的示例。例如,在数学方案中,如果候选人方法的答复输出与参考文献相同,则可以说该方法是高质量的。但是,在高差异的情况下 - 与写作一样,如果候选人的方法每次都会发布相同的答案,则可以说该方法是低品质。因此,“如果轨迹相似”不能是公正的判断标准。在这方面,Polar采用了另一种解决方案:相同方法生成的轨迹被用作阳性示例,并且不同技术生成的轨迹被用作负面示例。尽管此判断标准有一定的反义,但它是一个相关的信号,如果在其上进行判断,则是正确的。样本相似。我们可以想象方法的模型是某个分布的公正采样器。尽管单个采样可以使噪声与正面和负面示例相反,但是当采样量表增加并扩展到大尺寸时,将更准确地描述分布之间的差异和距离。如图2所示,使用上面的研究方案将极性的预训练阶段扩展到大尺寸。同一模型的一对输出样本用作阳性示例,不同模型的样本输出用作负面示例,因此可以知道奖励模型以识别策略分布而不是完全偏好的模型。在此阶段不需要人类的偏好数据。仅引入SFT微调的第二阶段才能与人类的偏好保持一致。图2:如何训练极地研究歧视性政策? - 通过自动合成数据完全构建了移动和首选的预测极性体积。具体而言,从LLM预训练的语料库中采样了大量的文本前缀,并从池模型池(由开放资源131个基本LLM和53个CHAT LLMS)中随机捕获模型进行轨迹采样。预训练的目标使用Bradley-terry损失:其中A1和A2表示由相同方法模型产生的轨迹(正样品对); B1表示不同策略模型(负样本)产生的轨迹。这样,Polar允许RM为Mala人将更高的奖励分配给相似技术生成的轨迹,从而明确建模差异和距离分布方法。在此阶段,Polar-1.8b总共使用了0.94T令牌预训练数据,而Polar-7b总共使用了3.6吨令牌的预训练数据。在微调阶段,使用少量偏好数据将极性与人类偏好对齐。在同一提示中,三个轨迹是样品,偏好-in -law被标记。 Bradley-terry损失也用于微调:其中A B C分别代表首选,次优和最差的轨迹。这种类型的偏好明确指的是“策略差异”,因为可以将其视为最佳策略分布的一巴掌,而C将能够考虑远离最佳策略的策略发行的策略。图3:极性训练的两个阶段(预训练和偏好微调)以及如何在RFT中使用极性如何使用极性? - 完美适应增强曲调。加固微调(RFT)是极地的最佳使用情况。传统的奖励模型已完全保存,无法根据参考标记,并且很难应用于外部领域情况。 rlvr虽然可能是正确的,还是基于参考的答案和政策,但很难在一般任务中扩展。极性完全符合RFT增强学习框架,并根据参考答案对模型的输出进行建模。如果模型的输出更接近参考答案,请获得更多的奖励金额。通过此培训过程,候选方法可以逐渐转移到最佳方法。极性有多有效? - 偶尔性能保证和一般1。样本显示:闭门和开放问题。以下显示了闭合末端和开放问题下的极性-7b标记的效果,并且从高到低标记显示。考试ES的测试被完全认为是轨迹之间的各种陷阱和细微陷阱,在边界情况下测试了它们的标记精度。封闭的问题:问题:“草莓”一词有多少个“ r”?参考答案:“草莓”一词包含3个字母“ R”。我们可以按字母来计算字母:“ S”,“ T”,“ R”,“ A”,“ W”,“ B”,“ E”,“ R”,“ R”,“ R”,“ R”,“ Y”。因此,答案是3。轨迹1(与参考完全一致):“草莓”一词包含3个字母“ r”。我们可以按字母来计算字母:“ S”,“ T”,“ R”,“ A”,“ W”,“ B”,“ E”,“ R”,“ R”,“ R”,“ R”,“ Y”。因此,答案为3。得分:-1.5380859375轨迹2(正确,想法正确):我们将计算“草莓”:“ s”,“ t”,“ t”,“ r”,“ a”,“ w”,“ w”,“ b”,“ b”,“ b”,“ e”,“ e”,“ e”,r“ r”,“ r”,“ r”,“ r”,“ y”。这里有三个“ R”,所以有三个答案。质量:-2.767578125曲目3(正确答案,不想法):“草莓”一词中有3个“ r”标记:-7.45703125曲目4(答案是错误的,正确的想法):让我们计算一下单词“草莓” lot“ r”:“ s”,“ t”,“ r”,“”,“ w”,“”,“”“”,“ r”,“ y”。这里有三个“ r”。 “ B”,“ E”,“ R”,“ R”,“ R”,“ Y”。 “ y”。对应于参考):1。秋季2。下降3。下降3。下雨3(正确答案):1。下降2。下降3。倾盆大雨3(类似于reference, another): 1. Downpour 2. Downpour 3 (similar to Reference, another): 1. -Idio): 1. Fall 2. Flood payment 3. Falling Upis 4 (Non -Idio): 1. Torrential Rain Score: -6.609375 TrackThe six (similar to reference, repeat one): 1. Torrential Rain 2. Torrential Rain Score 3. Torrential Score :. -7.234375跟踪十个(一个雨词,一个含义不匹配):1。降雨得分:-7.234375监视十个(一个单词降雨,一个含义,一个含义不匹配):1。TorrentialRain 2。雨水和雨水3。百分比分别是,并且能够准确地确定一般活动中的轨迹上的细微差异,例如推理,聊天和创造性写作,并准确地预测人类的偏好。值得注意的是,只有1.8b参数,Polar-1.8b可以取得与Skywork-Reward-27b和World相当的结果PM-72B-ultrafeffexp(参数分别为15次和40次),具有强极潜力。 3。RFT应用:综合增强LLM图5:加强实验,并进行了精制调整,导致RFT实验,极性仍然比开放的SOTA奖励模型更好。例如,与所有基准上的WorldPM-72B-72B-72B-72B-72B-72B-72B-72B-72B-72B-72B-利曲FeppEADED优化相比,Polar-7b微调的Llama-3.1-8B平均相关的9.0%与初步结果相关的9.0%。极性可以确定策略模型与训练前阶段之间的细微差异,而不是仅依靠一对注释偏好,而是对实际RL应用中的概括信号奖励的显着增强。实验结果表明,尽管极性1.8b和Polar-7b在偏好分析中的性能相似,但Polar-7b也对RL的花朵实验显示出显着的好处。将影响从1.8b提高到7b进一步描述了效果极性具有的缩放尺度的CT。它还没有直接描述当前传统基准台的可能限制,也就是说,与真正的刺激研究方案有很大的差异。 4。比例尺的影响6:极性滚动法律在下一个目标预测中类似于LLM目标的极性iSdisplays尺度定律。这进一步反映了极地无监督的预训练方法的巨大潜力。在法律关系中,验证集的丢失随着增加参数模型n的力量而降低。适当的幂律函数为L =0.9ÅN^-0.0425,R2值为0.9886。验证集的丢失在与权力的法律关系中也降低了最佳的训练计算C.适当的幂律函数为L = 2.4·C^–0.0342,R2值为0.9912。这些结果表明,提供更多计算源将继续带来更好的RM性能。极地缩放率的巨大影响旨在发展其发展更一般和Malakas奖励模型的巨大潜力。结论极性可以通过比较训练阶段的学习技术之间的距离来对齐人类的偏好。在相使用期间,Polar使用RFT范式进行LLM增强研究,显示出极好的暴力。作为一种新的训练前训练的预训练方法,Polar为后LLM培训带来了新的可能性,从而提供了有效技能解决方案的整体RFT目标。预计将打开最终缩放链接RL链接。 下一篇:没有了
 扫一扫,官方微信
|